
[Updated 8 June 13, to reflect addition of crime categorization data, as revealed by showCrime.]
I’m happy to announce the release of a new data set capturing details of crimes committed in Oakland between 2007 and 2012 inclusive, as reported by the Oakland Police Department (OPD) and augmented with additional information generated by Urban Strategies Council (USC).
OPD_combined_130415.csv (yanked; poor CSV formatting )
OPD_combined_130417.csv (replaced with version containing new crime categorization)
OPD_combined_130608.csv (zipped, 12.3 MB)
I want to thank in particular Steve Spiker and John Garvey for their help in interpretting USC results and providing additional address geocoding. (My many faithful readers will recall that I posted a similar, early analysis back in January 8, 2013; this version should be considered a second (and hopefully the last!) more refined analysis.)
Methods
This data is based primarily on a dataset specially requested from OPD IT personnel early in 2013: a historical record of all crimes in its database but reported in the same format provided as part of its (four month sliding window) FTP data set. The second dataset was developed by USC as part of a contract it had with OPD that terminated in 2011. The original version posted (to data.openoakland.org) by Spike in December, 2012 had serious issues. In collaboration with John and Spike, I helped them to produce a revised version with the final version posted 6 Mar 2013. However, remaining issues and uncertainty as to the provenance of other fields in USC’s data set has caused me to take conservative approach to including USC data into the dataset provided by OPD.
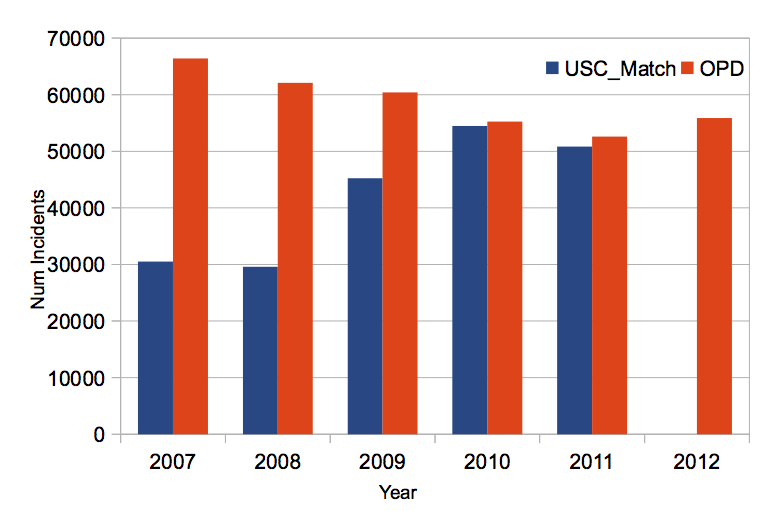
This figure shows the distribution of hits and misses across years shows first the obvious fact that OPD data set includes 2012 while the USC does not. Less clear, is why the USC data set is missing half of those incidents from 2007 and a quarter of those from 2009.
Nevertheless, when available the USC data set provides three key advantages. First, it provides geocodes (latitude,longitude coordinates) associated with crimes, while OPD records provide only addresses. Second, because of USC’s previous special status as an OPD contractor it was provided with information about multiple charges relating to the same crime. These more fine-grained elements are routinely kept within OPD but not provided as part of its public records resource. Third, USC went to the effort of associating statutes and UCR codes with the incidents.
The resulting data set captures nearly 400,000 records with valid dates occur between 2007 and 2012, inclusive. Critically, while only OPD data was available for 2012 (since this is after USC’s contract had expired), geocoding and crime classification has been attempted for these and other cases of missing USC data as described below.
Data dictionary
Fields are described below:
- Idx: arbitrary unique identifier within this data set
- OPD_RD: the crime identifier originally assigned by OPD
- OIdx: This field ranges from zero up to the number of individual USC records associated with a particular incident. Recall, while OPD only reveals a single record associated with each crime incident, multiple crime records are maintained internally. If one or more USC records are available, they are indexed with numbers 1, 2, 3 etc; when there are none, OIdx=0.
- Date: This is the date associated with the crime by OPD, normalized into the format YYMMDD_HH:MM:SS. [ cdate.strftime(‘%y%m%d_%H:%M:%S’)) ]
- CType: This is the text string crime description provided by OPD
- Beat: The police beat associated with the crime by OPD
- Addr,Lat,Long: The original source of this string was the OPD record. However, because addresses act as critique link to geocoding (latitude longitude coordinates), special procedures were used to normalize and “cache” address strings used more than once. This allows the efficiency of minimizing the number of required geocoding queries. A set of ~36,000 missing addresses were geocoded as part of a second effort done by John and Spike in early April, 2013. A by product of this process is that more complete, normalized addresses generated in this case. In particular, these generally include a zip code.
- Note this allows “extrapolation” from crimes for which addresses were geocoded, to provide geocodes for other crimes sharing the same address.
- UCR, Statute: In general, these fields were provided by USC. As noted above, there may be multiple records associating different UCR/Statute information with the same incident.
- A similar extrapolation is possible for missing UCR and statute attributes. That is, it turns out that for a large number of CTypes, the statute associated with this string is very probably (greater than 95% of the time) associated with the same statute. Similarly, UCR codes are in many cases highly (95%) associated with a statute. Using these procedures additional statute and UCR codes are also included in many cases.
- CrimeCategory: an element of the crime categorization hierarchy described in detail on this page.
Discussion
As I’ve already described, the situation surrounding crime data and its availability to citizens is in great flux these days. This historical data set is provided as a stop gap for preliminary analyses to inform the specification of future data sets.
Please let me know of issues you find in this data set (via comments below). I’d also be curious to hear of any analyses you do based on it, and will appreciate your mentioning this source.
thanks James, agreed! i’ve replaced it with a better version, using these specs:
csv.writer(outs, delimiter=’\t’, quoting=csv.QUOTE_MINIMAL)
let me know if you find any other issues.
i’ll post a sqlite .db version next.
The csv file can be correctly parsed with https://npmjs.org/package/rfc-csv for sure.
Using a csv generator for this file would be much easier on other parsers.